Normally ELAN allows to edit only a single file at a time. There are situations in which it is convenient to edit multiple files at once. The menu item gives a number of options to do just this. When selecting either of them, you are warned that you should have copies of the files you are going to work on in case you want to restore the files (there is no Undo for multiple file edits).
When you choose this option , you see the following dialog.
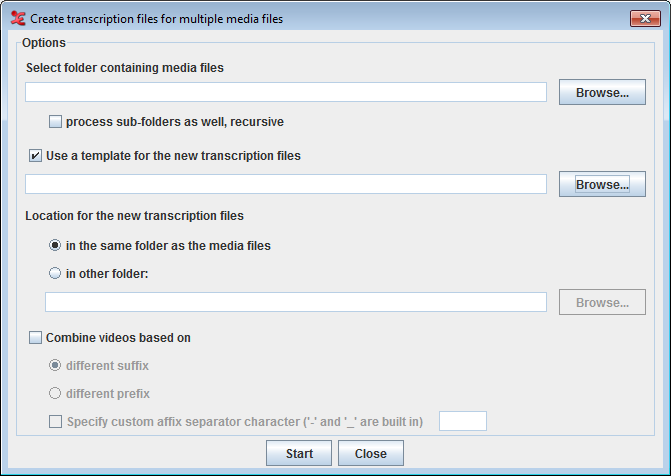
Options :
Select folder containing media files : click button to select the folder containing media files.
check this option process sub-folders as well, recursive to include all the media files in the recursive sub-folders of the selected folder.
To apply a template (only if required) for the new transcription files, check this option Use a template for the new transcription files and click on button to select the template file.
Next option allows you to select a location for the new transcription files.
To put the transcription files in the same folder as the media files, select in the same folder as the media files.
To put them in a different folder, select in other folder and click the button to select the destination folder.
You could always have more than one media file in a transcription. In order to group the media files for a transcription, check this option Combine videos based on. In order to define how the media should be grouped, select one of the following:
different suffix : to combine the media file with a different suffix and has the same file name.
different prefix : to combine the media file different preffix value and has the same file name.
To specify a separator in the filename to identify the suffix or preffix, check this option Specify custom affix separator character ('-' and '_' are built in).
Click on Start to create the transcriptions based on the options set.
The option shows, after clicking in the warning dialog mentioned above, the Multi File Editor. The first thing to do here is to load a domain by clicking . Loading a domain is the same as for the option. To be able to load a domain you must of course have created one beforehand(see Section 4.9.1). After loading a domain, the data is shown in the table. In this table you can edit tiers on the Tiers tab and linguistic types on the Linguistic Types tab.
To edit a name, annotator or participant of a tier, double click the corresponding table cell or select it and start typing. To change the linguistic type of a tier, select one from the drop down menu. You can add a tier by clicking , add a depending tier by clicking and remove one by clicking .
![[Note]](images/note.png) | Note |
|---|---|
If there are hierarchy inconsistencies (e.g. if a tier in one file does have a parent while a tier with the same name in another file does not) removing tiers is not possible. The button is therefore greyed out. |
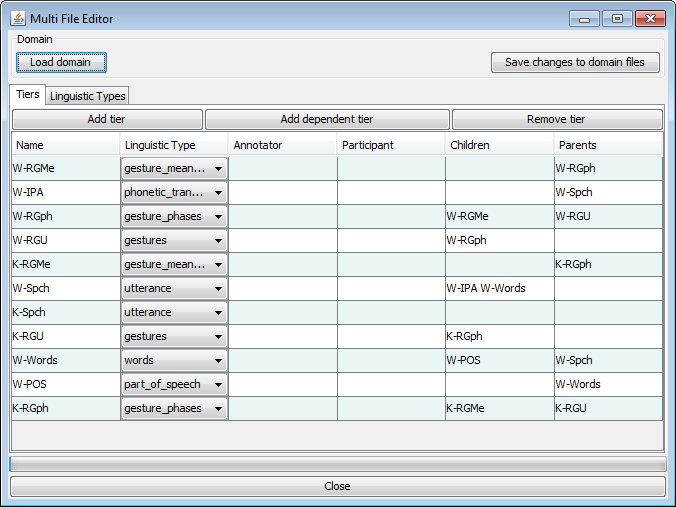
On the Linguistic Types tab, the name of a linguistic type can be changed by
double clicking the corresponding table cell in the Type Name
column.
Changes made in the Tiers and Types tabs are applied to all the files in the domain after clicking the Save changes to domain files button.
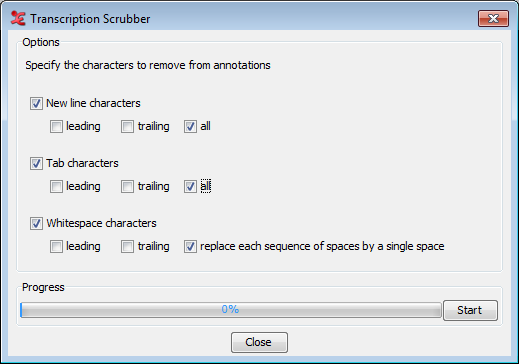
When you choose , you first need to specify a new domain or select an existing domain. This option helps you to "clean" the annotation files (*.eaf) of possible tabs or whitespace characters which are often overlooked by the user but are still saved in the file. To select, create or delete a domain see Section 4.9.1.
In the next dialog, you can specify what characters to delete, new line characters, tab characters and/or whitespace characters, and in what position these characters have to be. Click to start the scrubbing process. The progress of the scrubbing is shown in the progress bar.
The option for multiple files is the same function as annotations from overlaps in the current open file (see Section 5.12.1 ), but applied to a selection of files. The first step allows to select a custom set of files in a file browser or to load a set of files that have been stored as a domain. For loading or creating new domain see Section 4.9.1 The list of tiers is the sum of all tier names encountered in the selected files. The options in the next steps are the same, clicking the Finish button in the last step the new tier is created and populated with annotations in all files of the domain.
The option for multiple files is the same function as annotations from subtraction in the current open file (see Section 5.13 ), but applied to a selection of files. The first step allows to select a custom set of files in a file browser or to load a set of files that have been stored as a domain. For loading or creating new domain see Section 4.9.1 The list of tiers is the sum of all tier names encountered in the selected files. The options in the next steps are the same, clicking the Finish button in the last step the new tier is created and populated with annotations in all files of the domain.
This function is similar to annotation statistics for the current file (see Section 5.16.2). The main difference after selecting the files in the domain is that it is possible to select which tiers to include in the calculations. The tables in the tabs do not have the column showing the total annotation duration as a percentage of the media duration but most do have a column for the number of files a certain value (tier or type name etc.) has been encountered in. After changes in the selection of files or in the selection of tiers the Update Statistics button needs to be clicked before the new calculations are started.
Since ELAN 4.7, you are able to do an N-Gram analysis over multiple eaf files. This functionality has been developed by Larwan Berke, you can find an extensive PDF document about this implementation on the third-party resources page of ELAN: http://tla.mpi.nl/tools/tla-tools/elan/thirdparty/
When you first open the N-gram analysis, a new dialog window will pop up that contains the various options for the search and the resulting table showcasing a few statistics.
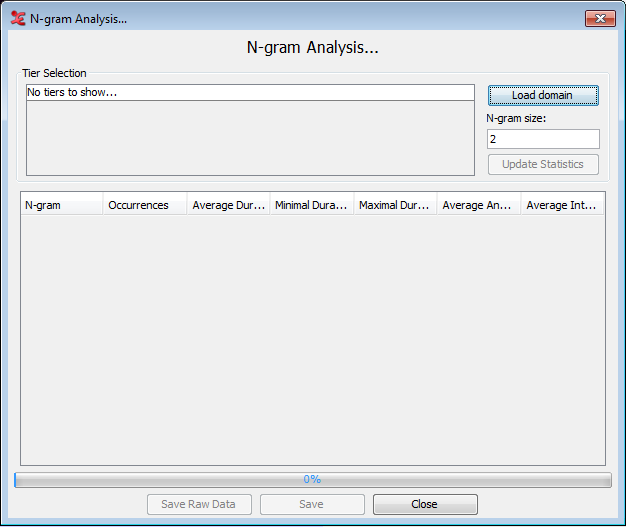
The first step is to select the search domain, see Section 4.9.1. Once that is done a list of tiers seen in the domain will be shown. A note of caution: the code assumes that all files in the domain will contain the same tiers. It then loads the first file in the domain to extract the tiers and display it in the window. Check the tiers you want to analyse.
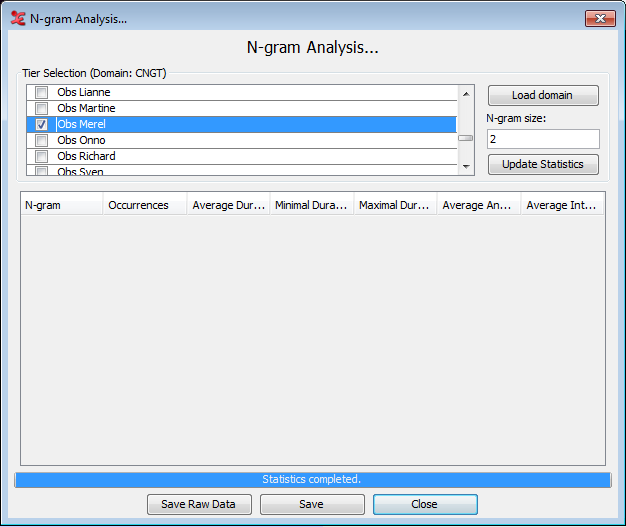
Next, define the N-gram size in the textbox. The software can handle any positive size greater than 1. When set, clicking the “Update Statistics” button will start the search and will calculate the statistics. The annotations are extracted from the files, N-grams created from them, and finally collated into groupings of same N-grams for statistical analysis. When done, you will see a pop-up window with a process report. If there were any errors, they will also be displayed here.
When the search is done, the result table will be displayed in the main window. Some of the columns from the data are visible here, however only a small subset is displayed simultaneously to avoid overcrowding the GUI. The visible columns are: N-gram, Occurrences, Average Duration, Minimal Duration, Maximal Duration, Average Annotation Time, and Average Interval Time.
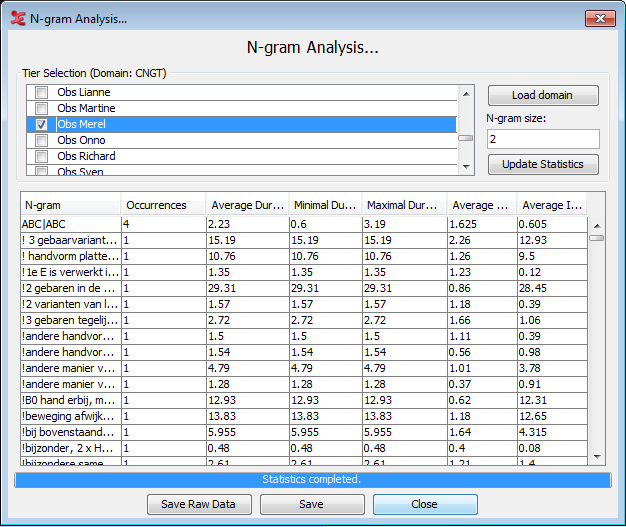
The first column shows the N-gram. The vertical marker “|” separates the annotations contained in the bigram. For example, if a trigram was selected it would show something similar to “FINISH|READ|BOOK” and so on for larger N-gram sizes.
Finally, in order to see the entire data that was produced it is necessary to export the results into a text file for further processing. This is done by clicking on the “Save” button and a dialog will pop up asking the user where to save the data. It is exported in a CSV-like format (Comma-Separated Values). The CSV file uses tabs “\t” as the delimiters and newlines “\n” as the record separators to avoid ambiguity with the values. A sample row is: “HOLD|IX-1p\t7.9934\t0.348\t0.13754 ...” and contains numerous columns.
Furthermore, it is possible to export the N-grams individually in order to process it separately from ELAN. The data is exported by clicking the “Raw Data” button in the GUI. After supplying the file the data will be exported in the same CSV format as discussed above. For more in-depth information about the N-Gram analysis function and the resulting data, please consult the PDF mentioned earlier on the ELAN website, or consult it here: https://parasol.tamu.edu/dreu2013/Berke/images/DREU_Final_Report.pdf (This link may become outdated at some point).
Apart from exporting part of a clip in a project (see Section 4.4.1.16), you can also export multiple clips from the same (or multiple) projects. The clips will be clipped based on the annotation-times on a specified tier.
As with the exporting of a part of a clip, Windows users will need to put a copy of ffmpeg.exe or ffmbc.exe in the program folder of ELAN. ( see Section 4.4.1.16) for more info.
To ultilize this function, you will need to create a tab-delimited text file first. Go to > > . (note, this will not work for the single file tab-delimited export, as there is no option to include the videofile-path). Choose a domain, or create a new one (if you want to create multiple clips from only one .eaf, create that .eaf as a new domain). Select the tiers you want to include in the Tab-delimited text file (each annotation on a tier will result in a clip).
Make sure you check the following options:
Exclude tier names from output
Exclude participant names from output
Include file path column
Under the time column and format options, you will need to check:
Begin Time
End Time
Duration
ss. msec
The other options have to remain unchecked. Next, click and the file will be exported to a text file.
Go to > > . Choose the exported tab delimited text file you just created, and specify a folder to save the clipped videos to. Click to start the process. When done, a process report dialog will appear with information about the clipping process.
Similar to merging tiers within a single project (see Section 5.4.6), this function allows you to merge tiers in multiple projects. This means the merged tiers will be added to each project you select in the process.
To start, click > > . You will be presented with a dialog in which you either select the eaf files from the file browser, or select files from a domain. When done, select the tiers to use for the merging process.
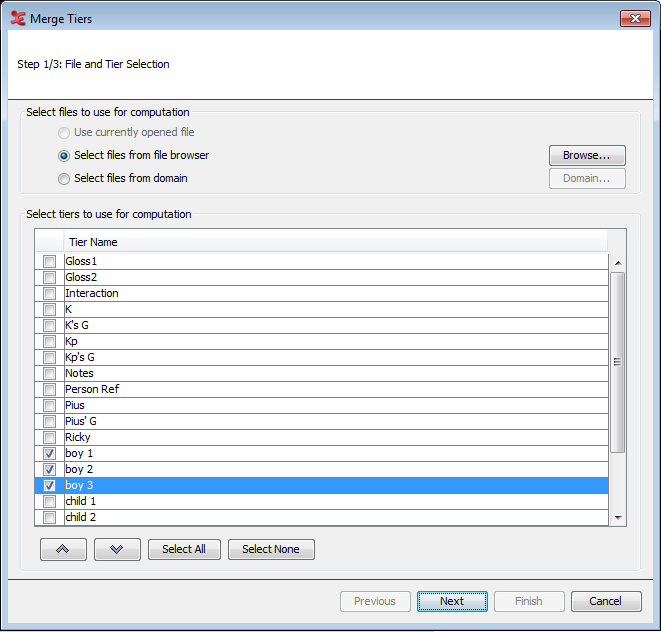
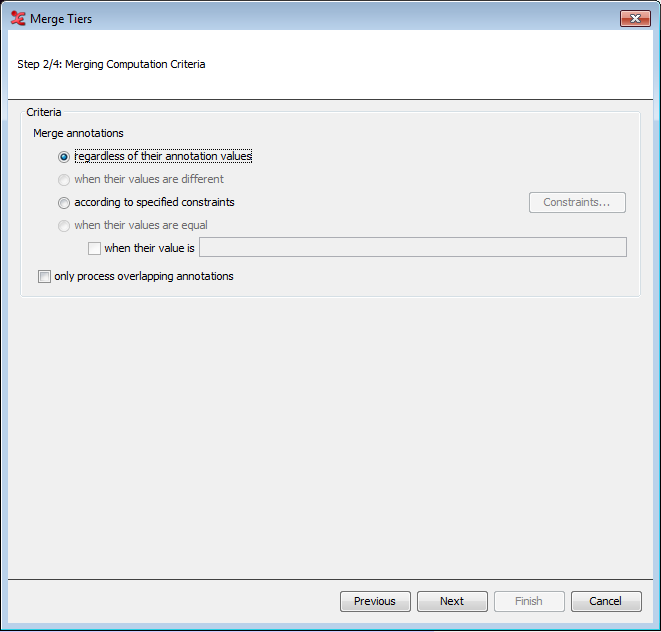
Next, select the merge criteria, either regardless of the annotation values or according to specified constraints within the annotations of a chosen tier. When checking the option Only process overlapping annotations , Elan only merges annotations that have the same value. In this case, the values of both annotations are not concatenated, so the created annotation contains the value only once.
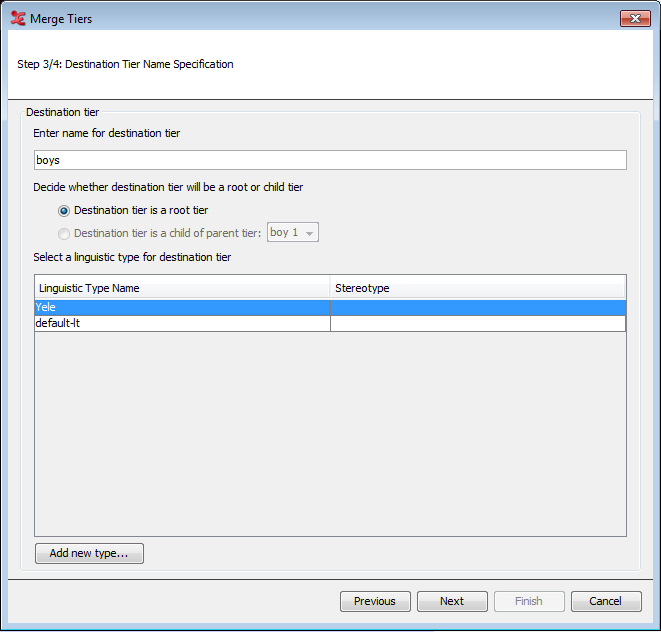
In the next step, set a name for the destination tier and decide whether this tier will be a root tier or a child tier. Also select or create a linguistic type for the new tier.
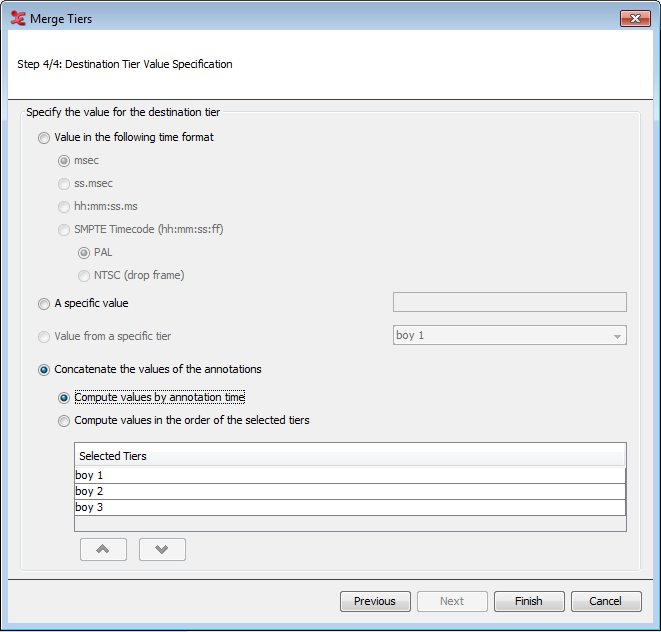
Lastly, specify the value for the destination tier. You can set a value in a time format, which will put in the specified time values inside the annotation units on the new tier. You can also choose to set a specific value to be filled out into the annotation units. The final choice is to concatenate the values of the annotations from the tiers you have selected for merging.
After clicking , the tiers will be merged and inserted into each eaf you chose at the start. A process report will show an overview of what has been done.